

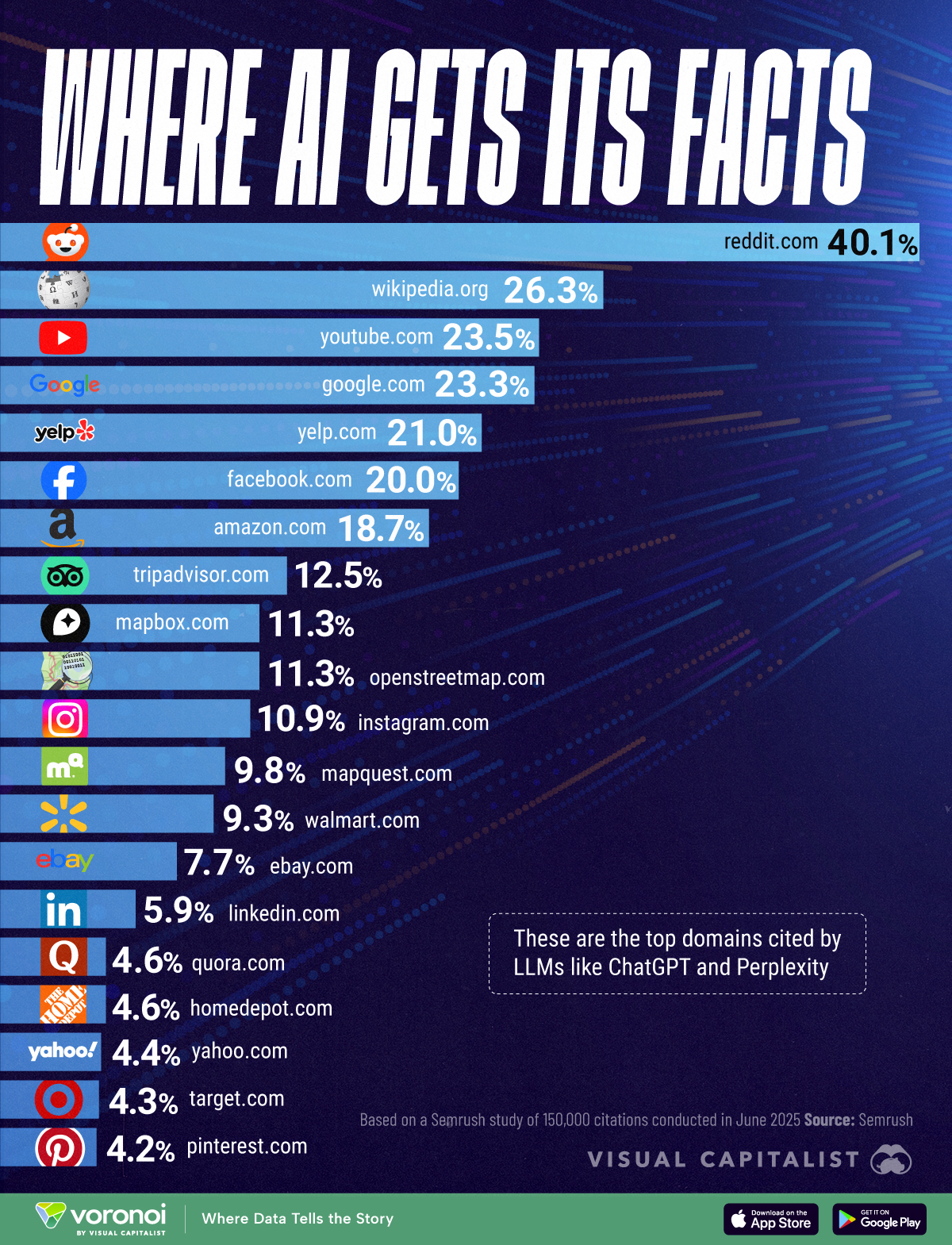
Mākslīgā intelekta rīku zināšanas nerodas nekurienē, tās tiek izgūtas no dažādiem avotiem. Semrush analītiķi aplēsuši, kuras tieši vietnes ir populārākās, kad ChatGPT un citi līdzīgi mākslīgā intelekta risinājumi atbild uz taviem jautājumiem.
Noskaidrots, ka visplašāko informāciju par dažādiem faktiem mākslīgais intelekts paķer no Reddit un Wikipedia. No šiem diviem minētajiem avotiem mākslīgais intelekts izgūst divas trešdaļas savu zināšanu. Ģeogrāfiskos jautājumos mākslīgais intelekts paļaujas uz Mapbox un OpenStreetMap datiem.
Pētnieki analizēja 150 000 atbilžu, ko sniedza dažādi mākslīgā intelekta čatboti. Pamatā šādi mākslīgā intelekta čatboti paļaujas uz cilvēku radītu saturu un internetā atrodamām atbildēm, bet čatboti nereti arī kļūdās, kā arī Reddit un Wikipedia nav uzskatāmi par 100% precīziem avotiem.
Mākslīgā intelekta čatboti vēl arvien var izplatīt dezinformāciju un propagandu, jo mākslīgais intelekts tikai atkārto avotos sagrābstīto informāciju. Tas pats attiecas uz bieži atkārtotām muļķībām (sveiciens plakanzemes idejas piekritējiem), kā arī nevajadzētu paļauties uz mākslīgā intelekta čatbotiem, kad runājam par būtiskiem dzīves jautājumiem par finansēm, veselību un juridiskām problēmām.


Tas nekas, ka kopsumma ir virs 100%?
Mākslīgā intelekta pasaulē tas ir absolūti nekas traks :)
Acīmredzot tur domāts, MI atbildes vidējais satura avots. Viena atbilde var saturēt informāciju no vairākiem avotiem
Agdieuz, Reddit izmantot kā informācijas avotu, šī tiešām ir laba doma 😁